I got a series of Rollbar alerts a few days ago: NoMemoryError: failed to allocate memory. The application wasn’t under any particular load at the time, and a quick look at memory usage stats in appsignal showed the telltale signs of a memory leak: slowly but inevitably rising memory usage.
A needle in a haystack
We had not noticed similar errors before, so my first thought was “what have we changed?”. As it turns out, nothing - the leak had just flown under the radar. The leak is pretty slow, so between deploys and instances scaling up and down due to variations in load, it was actually pretty rare for any given instance to be up long enough for the leak to have any real consequences. On the rare occasions it actually impaired functionality it was handled automatically as any instance failure would be.
I started the proverbial hunt for a needle in a haystack with Richard Schneeman’s excellent derailed_benchmarks tool ( the perf:mem_over_time variant ). I didn’t really know what I was looking for though and wasn’t able to find anything very significant - I tried some of the app’s most hit endpoints but wasn’t able to reproduce the leak. Clearly there was a combination of circumstances or a difference in our production setup I was overlooking.
rbtrace to the rescue
My next port of call was rbtrace, via Sam Saffron’s excellent blog post on debugging memory leaks. The basic idea is to use rbtrace to run ObjectSpace’s debugging tools inside the Rails app running in production.
To get the most out of this you need to tell ObjectSpace to collect some details from each memory allocation by calling ObjectSpace.trace_object_allocations_start. This has a noticeable overhead (both in terms of performance and memory), so I did this against a single Passenger instance. When using with Passenger, you need to set rbtrace to not be loaded by bundler (require: false in the Gemfile) and instead load it from a controller after the app is up (see https://github.com/tmm1/rbtrace/issues/9).
Then it’s much as Sam describes:
1
| |
To dump a file with allocation info. I ran his first analyze script to aggregate the data and got some output that looked a little like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
(If you find everything reported as an empty generation (as I did at first), then you’ve probably forgotten to call ObjectSpace.trace_object_allocations_start).
A slow but steady leak. Digging into what code was leaking objects the allocation locations were mostly like this:
1 2 | |
Which was a little surprising - I was expecting to see some of our application code here. I eyeballed some of the actual values and they were the names of the methods that views get compiled into. This didn’t make any sense: in production Rails caches compiled views, so I should have a flurry of these when the app has just restarted but nothing once the app gets into a steady state.
Template caching
After a few minutes double checking that template caching was actually turned on (it was) I decided that I needed to understand more about how template caching worked - maybe something was invalidating this cache? Off I went spelunking through the Rails codebase.
I fairly quickly found that this cache lives inside ActionView::Resolver but it wasn’t used in the way I had assumed. I had thought there’d be one big resolver (with its cache), whereas there are often are multiple resolvers (and hence multiple caches).
A Rails controller has a view_paths attribute, which is conceptually a list of paths to search, but is actually a ActionView::PathSet that contains many ActionView::Resolver objects (one for each path), i.e. each element in view_paths is cached separately.
At this point it seemed logical to see if something was changing view_paths - maybe that would explain things. A quick search through our codebase found the following controller instance method:
1 2 3 4 5 | |
This app doesn’t actually have a separate mobile site anymore - mobile_site_requested? is always true in the real world, although it is technically possible to request the old versions of the pages. This is hangover from when we redesigned the site from desktop only to a responsive, mobile first, site. A candidate for clearing up for sure, but it seemed pretty harmless.
When I did this in Rails console (looking for the outfits/show template)
1
| |
It consistently returned the same object_id: the cache was being used. On the other hand
1 2 3 | |
resulted in a different template object for each controller, so prepending a view path like this was resulting in the cache not being used (for views in app/views/mobile). This felt like I was definitely onto something!
The Rails code for prepending a path looks like this
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
So when you prepend a string, Rails creates a new resolver for that path and adds that to the path set. When done from a controller instance method, this means that each request uses a new resolver for app/views/mobile (with an empty cache). Memory leak aside, my code was bad because it meant views were compiled over and over again.
Now that I understood that prepend_view_path was key, I knew why I wasn’t able to reproduce the leak earlier - I’d forgotten about this part of the app and had been testing against a codepath that didn’t use prepend_view_path. Once I adjusted my test setup I was able to see the same leak using derailed.
The actual leak
I was still curious about the actual leak: compiling templates over and over again was bad, but why was it leaking? The leaked values were the names of methods, which are symbols. Ruby garbage collects symbols since ruby 2.2, so how is this possible?
Although the headlines were “Ruby 2.2 adds Symbol GC”, the reality is a little more complicated. There are two kinds of symbols: mortal and immortal ones. Immortal ones are (simplifying grossly) used by the C parts of ruby and not collectable. Defining a method creates an immortal symbol (or transitions a symbol from mortal to immortal) so creating large numbers of methods with unique names will still cause a leak, even if you undefine the methods when you are done (see https://www.slideshare.net/authorNari/symbol-gc for more details on symbol GC).
It was a pretty small leak - a hundred or so bytes per distinct template or partial rendered per request, but this app gets over a million requests a day, so it all adds up. It does like this may have bitten other people before - see rails#22580 and rails#14301
Fixing it
In this very particular case the use of prepend_view_path was unnecessary and would be possible to just remove it. This isn’t always the case - we’ve got other apps which do actually need to use prepend_view_path (for example a white labelled application that has per request host view overrides) - so I wanted to see if I could fix the leak while keeping prepend_view_path.
prepend_view_path only creates a new resolver if you give it a string or pathname - if you give it a resolver, it will just add that to the array. Therefore we just need to create (and cache ourselves) an ActionView::Resolver (i.e. replicate what the typecast method was doing above), and prepend that instead of the string.
1 2 3 4 5 6 | |
Results
This is a graph of memory usage across the hosts for this application either side of when the fix above was deployed.
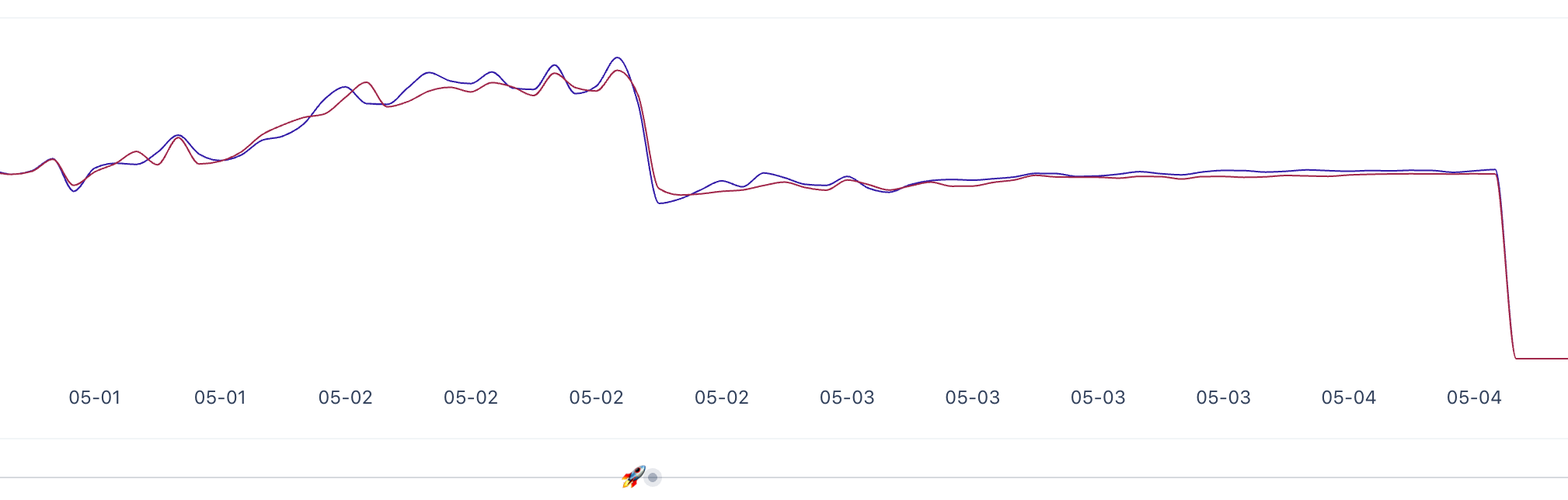
Pretty convincing! (Graph from appsignal)